1. Full Custom Design Flow
A full custom design flow starts a level lower than that required for semi-custom with the creation of a library of cells. These can then be combined together to build up the complete design. As in a semi-custom process each cell must have a transistor level circuit, an internal mask level layout, a functional model for simulation and an abstract outline for placement and routing. The designer must provide all of these as detailed below.
1.1 Cell Design
Cells can be designed in a number of ways. By far the most specialised method is to employ a graphics editor to create and combine a series of polygons. These represent the individual masks that make up the constituent components of the required transistor circuit. A detailed knowledge of mask level geometry is required together with an understanding of process design rules so that correctly defined components can be constructed and manufactured. The following example details a transistor circuit for a CMOS inverter together with its associated mask level layout.
Figure 1.1 Cell Design
A modern CMOS process can have upwards of a dozen masks to define the complete design. Each will be used to pattern various device elements and their associated interconnect. The main masks required are detailed in the layout above and are listed and described below.
| MASK |
DESCRIPTION |
|---|
| Nwell |
An area of the p-type substrate that
will be diffused with n-type impurity to construct the
pmos device. |
| Active Area |
The areas in the nwell and substrate
where the pmos and nmos transistors respectively will
be patterned. |
| P Diffusion |
The p-type diffusion for the pmos device. Also a ground
connection from the gndvss power rail to the substrate. |
| Polysilicon |
The transistor channels. Whenever polysilicon crosses
an active area a transistor is formed, with source and
drain areas either side of the channel and the polysilicon
forming the gate connections. |
| Metal 1 |
The lower level metal interconnect. |
| Metal 2 |
The upper level metal interconnect. |
| Contact |
Metal 1 to diffusion/polysilicon connection. |
| Via |
Metal 1 to metal 2 connection. |
An alternative method of defining the cell layout information is to use a Layout Synthesiser. Here the mask data is now automatically generated from the circuit schematic. The Cadence design system provides this facility. Typically in a full custom topology, cells will be arranged in rows. If all cells have the same height but variable widths they can be horizontally butted and power supply rails can then be tracked straight along the rows. In order to accomplish this a layout synthesiser can compact the cells to a predetermined height. This is also more area efficient. The diagram below shows a layout for the CMOS inverter circuit generated and compacted by a layout synthesiser.
Figure 1.2 CMOS Inverter Circuit
1.2 Cell Verification
In order to verify correct functionality for each cell a circuit simulator such as SPICE/Spectre will be employed. The designer will be required to specify appropriate signal and power supply sources to test the cell in all its operating modes. The following diagrams illustrate a test circuit for the CMOS inverter together with obtained simulation results.
Figure 1.3 Cell Verification
The circuit is powered by a voltage source V1 set at 5 volts to equal the power supply of the chip.
A pulse is applied by voltage source V0 set to swing between 0 volts and 5 volts with rise and fall times equal to 1 picosecond.
The gnd ground connection provides SPICE with a path down to 0 volts.
Components specified purely for testing, like the voltage sources, will need to be removed before the cell layout is defined.
Alternatively these components can be specified in an accompanying stimulus file.
Figure 1.4 Cell Verification
The simulation results enable two important characteristics to be determined for use by the logic simulator.
1) The functionality of the cell. This will be used to define an appropriate logic expression in the functional model.
2) The switching times of the cell measured on the edges of the output waveform. These will be used to define the rise and fall times in the functional model.
1.3 Cell Functional Model
When cells are combined to form the complete design it becomes impractical to simulate this at the circuit level. Simulators such as SPICE cannot handle the resulting complexity and will fail to produce a result. If the design is digital we can construct a functional model for each cell and utilise a gate level logic simulator, such as Verilog, to simulate the assembled design. This is exactly what happens in a semi-custom process except that these functional models have already been provided by the silicon foundry designers. The following text details a typical Verilog functional model for the CMOS inverter.
`timescale 1ps / 1ps
`define min_typ_max (0.26:0.5:1.34)
module inverter (A, NOTA);
output NOTA;
input A;
specify
(A*>NOTA) = (`min_typ_max*1600, `min_typ_max*1700);
endspecify
assign NOTA = !A;
endmodule
The `timescale statement defines the time units to be picoseconds.
The `define statement defines a variable array min_typ_max representing scaling factors to be applied to rise and fall times for minimum, typical and maximum operating conditions.
The specify statement defines rise and fall times from input A to output NOTA (1600ps and 1700ps respectively) and computes the overall values for minimum, typical and maximum operating conditions.
The assign statement provides the required logic expression ( ! indicating the invert function).
1.4 Cell Abstract
The cell abstract is generated from the cell layout. It consists only of a cell outline with contact points for the power supply connections and the cell inputs and outputs.
Figure 1.5 Cell Abstract
Here we see the cell abstract representing the CMOS inverter layout.
The abstract has been automatically dimensioned to match the height of the other cells in the design.
Contact points for the power and ground rails (pwrvdd! and gndvss! respectively) have been assigned at the top and bottom of the cell. This allows continuous routing along a cell row.
Contact points for the input and output signals (A and NOTA respectively) have been assigned both on the top and bottom edges of the cell. This allows the router to make input and output connections from routing channels either above or below the cell, whichever is the most convenient.
1.5 Design Layout and Verification
The layout strategy employed depends on whether the design is completely full custom or largely standard cell with some full custom components.
In a full custom design flow we will need to utilise a layout editor to manually place and route the cell abstracts in an appropriate topology. Typically this will comprise a number of cell rows separated by routing channels. Cells will be placed along the rows and the interconnect tracked along the routing channels. During this process two types of error can be introduced. The first is a violation of the process design rules, for example placing metal tracks too close together. These errors are identified by running the design through a Design Rule Checker (DRC) which can highlight any violations on the layout. The second is an incorrect connection of cells. These are identified by running the design through a Layout Versus Schematic (LVS) checker. This compares the connectivity of components on the schematic with those on the layout and lists any differences.
In a standard cell design flow we can choose a manual or automatic layout or a mix of both. An entirely automatic layout would treat the full custom cells the same as the standard cells and place and route in the normal way. If required we can place and route the full custom cells separately (as is also possible for any standard cell requiring special treatment) and then complete the layout automatically. Alternatively the entire layout can be implemented manually but this is not common. If there has been any manual intervention in the layout process it is essential that both a DRC and LVS are performed to check for errors.
3.3 Complex Gates A library of full custom cells will always comprise the basic primitive functions NOT, AND, NAND, OR and NOR. Additionally there will also need to be some more complex functions such as AND/OR, OR/AND, Multiplexor, Comparator elements etc. These can be assembled using the primitive cells but a more area/speed efficient implementation is achieved by designing these as Complex Gates.
2. Complex Gate
2.1 Complex Gate Structures
The following examples illustrate a variety of possible implementations for the function F = a' b' + c' d' 1) NMOS Primitive Gates
Figure 1.6 Complex Gate Structures
Using standard component library cells in NMOS 5V technology with Zpull-up/Zpull-down > 4/1
Each NOT gate requires 5 transistors (4 x depletion pull-up and 1 x enhancement pull-down).
Each AND gate comprises a NAND gate followed by a NOT gate and requires 15 transistors. The NAND gate needs 10 transistors (8 x depletion pull-up + 2 x enhancement pull-down) and the NOT gate needs 5 transistors again.
The OR gate comprises a NOR gate followed by a NOT gate and requires 11 transistors. The NOR gate needs 6 transistors (4 x depletion pull-up and 2 x enhancement pull-down) and the NOT gate needs 5 transistors again.
The total number of transistors to implement the function is: 4 x NOT gates @ 5 transistors + 2 x AND gates @ 15 transistors + 1 x OR gate @ 11 transistors = 20 + 30 + 11 =
61 transistors.
2) CMOS Primitive Gates
Using this technology we can assume that p-type and n-type transistors are of equal size.
Each NOT gate requires the area of 2 transistors.
Each AND gate requires the area of 6 transistors (4 for the NAND function and 2 for the NOT function).
The OR gate requires the area of 6 transistors (4 for the NOR function and 2 for the NOT function).
The total number of transistors to implement the function is: 4 x NOT gates @ 2 transistors + 2 x AND gates @ 6 transistors + 1 x OR gate @ 6 transistors = 8 + 12 + 6 =
26 transistors.
3) NMOS Complex Gates
Start from the standpoint that any NMOS function has a built-in inversion. So either focus on constructing the inverse function (F') from the outset or accept that a NOT gate will be required to derive the output.
Figure 1.7 NMOS Complex Gates
The inverse function is: F' = (a' b' + c' d')'
Using DeMorgan's law F' = (a' b')'. (c' d')'
Using DeMorgan again F' = (a + b) . (c + d)
[DeMorgan's law states that an inverse logic expression can be obtained by inverting each of the terms in the expression and changing all the AND terms to OR and all the OR terms to AND].
Figure 1.8 NMOS Complex Gates
The total number of transistors required = 8 x depletion pull-up and 4 x enhancement pull-down =
12 transistors
It will be considerably faster than the designs based on standard library cells.
4) CMOS Complex Gates
One way of constructing a CMOS complex gate is to use the inverse function ( F') to form the pull-down element and the true function (F) to form the pull-up element.
Figure 1.9 CMOS Complex Gates
Therefore in our example:
The pull-up section implements the function F = a' b' + c' d'
The pull-down section implements the function F' = (a + b) . (c + d)
Figure 1.10 NMOS Complex Gates
Assuming p-type and n-type transistors are of equal size the total area required =
8 transistors.
This design would be slightly faster than the one in NMOS.
Summary
A design in NMOS using simple gates drawn from component libraries would require the area taken up by 61 transistors. Using a different technology, CMOS, the same design would be accomplished using 26 transistors. By employing complex gates and NMOS the design can be implemented with 12 transistors and would be considerably faster. Using complex gates and CMOS requires just 8 transistors and the design would be slightly faster again.
2.2 Complex Gate Design
The following methodology is suitable for the design of complex gates.
Example - Implement and optimise the following function: Z = [A B + C(A + B)]'
The optimum implementation will involve CMOS.
The equation for the inverse function forming the pull-down section is Z' = [A B + C(A + B)]'
This equation needs to be manipulated to obtain the inverse function for the pull-up section.
Z = (A.B + C(A + B))' by DeMorgan
= (A.B)' . (C(A + B))' by DeMorgan
= (A.B)' . (C' + (A + B)') by DeMorgan
= (A' + B') . (C' + (A'.B') simply expanding the equation
= A'.C' + A'.B' + B'.C' + A'.B' removing the repeated expression
= A'.C' + A'.B' + B'.C'
Z = A'.B' + C'. (A' + B')
Figure 1.11 Complex Gate Design
Note: In this particular example the pull-up section and the pull-down section are identical in structure. This, however, is unusual.
2.3 Complex Gate Optimisation
As we have seen, complex gate structures utilise the lowest number of transistors so are inherently efficient in area and switching speed. Careful design, however, can ensure that these parameters are optimised.
Optimised area is obtained by ensuring that the transistor channel widths (W) and lengths (L) are set to the minimum dimension of the fabrication process. These are referred to as Minimum Feature Size devices. For example, in a 0.8 micron process each transistor would have W = L ~ 0.8 micron. This has implications, however, both on the relative switching times and drive capability of the gate. With minimum feature size devices we would expect to have rise times longer than fall times due to the difference in mobility between holes and electrons exhibiting unequal resistance in the p-type and n-type sections. We can compensate for this by increasing the width of the PMOS devices but this takes more area. Likewise with drive strengths. The gate will sink a logic 0 through a lower resistance n-type section better than it will source a logic 1 via a higher resistance p-type section. We can compensate for this with larger PMOS devices but again this requires more area. Typically unless there are specific requirements for equal switching speeds and drive strengths device sizes will be kept to a minimum.
Optimised speed is obtained by:
- Minimising the paths between the gate output and supply rails, Vdd(Power) and Vss (Ground).
- Minimising output capacitance.
- Organising the circuit such that the transistors that are activated later are closest to the gate output.
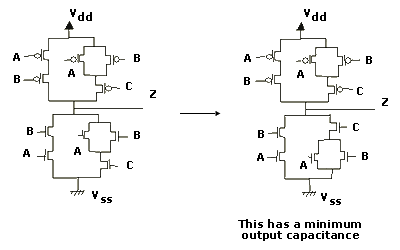
Taking the example design.
The first design rule is satisfied, there are only two gates between the output and each rail.
An improvement can be made to satisfy the second design rule. The layout should be organised slightly differently to minimise the number of gates connected to the output and so ensure that the output capacitance is a minimum as shown below.
Figure 1.12 Complex Gate Design
3. Pass Transistor Networks
An alternative approach to the standard logic design techniques so far discussed is to think of a digital circuit as a network of series and parallel switches. In this kind of topology we have some input variables controlling the switches, others as data inputs to the network and transistors utilised as the switches. These transistors are referred to as Pass Transistors since they pass data from input to output. The circuits to be considered utilise n-type devices in an NMOS process.
The following truth table defines a pass transistor network for a 2 out of 3 majority function.
ABC F The output is a logic 1 whenever two or more inputs are a logic 1
000 0 The required logic equation is :-
001 0 F = AB + BC + AC
010 0
011 1
100 0
101 1
110 1
111 1
The resulting pass transistor implementation is shown below.
Figure 1.13 Pass Transistor Networks
The variables A and B are used as control variables whilst logic 1, C and logic 0 implement the data lines. Thus when A=B=0 for example the two transistors in the top branch of the network are activated and the input (logic 0) is passed to the output.
The design of pass transistor networks requires a re-arrangement of logic expressions into a more suitable form. Shannon's Theorem provides the required manipulation.
3.1 Shannon's Theorem
The theorem states that any logic expression can be expanded into two terms, the first with a particular variable set to 1, and multiplied by that variable, and the second with it set to 0, and multiplied by the inverse of that variable. By repeating Shannon's theorem with each of the variables involved in the expression, the fullest reduction can be achieved. The method lends itself to automation. It is particularly useful in multiplexor and pass transistor circuit design.
Shannon's theorem is stated in a generalised form like this:
A function of many variables, f(a0, a1, a2, ..., ai, ..., an) can be written as the sum of two terms, one with a particular variable (say ai) set to 0, and one with it set to 1.
f(a0, a1, a2, ..., ai, ..., an) = ai' f(a0, a1, a2, ..., 0, ..., an) + ai f(a0, a1, a2, ..., 1, ..., an)
Example
Let's say the function f(a,b,c,d) is defined as f(a,b,c,d) = a b d + a' c
When a is zero, fa=0 = 0 b d + 1 c = c
When a is one, fa=1 = 1 b d + 0 c = bd
Now using Shannon, f(a,b,c,d) = a'fa=0 + afa=1 = a' (c) + a (b d)
Shannon can be generalised for more than one control variable.
Example using two control variables
Starting with the same function f(a,b,c,d) = a b d + a' c
f = a' b' fa=0&b=0 + a' b fa=0&b=1 + a b' fa=1&b=0 + a b fa=1&b=1
=
a' b' (c) + a' b (c) + a b' (0) + a b (d)
Example using three control variables
Starting with the same function f(a,b,c,d) = a b d + a' c
f = a' b' c' fa=0&b=0&c=0 + a' b' c fa=0&b=0&c=1 + a' b c' fa=0&b=1&c=0 + a' b c fa=0&b=1&c=1 + a b' c' fa=1&b=0&c=0 + a b' c fa=1&b=0&c=1 + a b c' fa=1&b=1&c=0 + a b c fa=1&b=1&c=1
=
a' b' c' (0) + a' b' c (1) + a' b c' (0) + a' b c (1) + a b' c' (0) + a b' c (0) + a b c' (d) + a b c (d)
3.2 Pass Transistor Design
Shannon's theorem will be applied using n-1 variables as controls and three data lines namely 1, 0 and the remaining nth variable. Let the control signals flow vertically and the data flow horizontally.
Place n-type transistors at the intersections to satisfy the expanded Shannon function.
Remove pairs of transistors where they cancel one another out.
Example
f(a,b,c,d) = a b d + a' c
= a' b' c' (0) + a' b' c (1) + a' b c' (0) + a' b c (1) + a b' c' (0) + a b' c (0) + a b c' (d) + a b c (d)
Figure 1.14 Pass Transistor Design
Figure 1.15 Pass Transistor Design
The construction of a pass transistor network must be such that one and only one branch is active at any given time. If more than one branch is active the output can be connected to different logic levels thereby resulting in a corrupted output. Having none of the branches active renders the output of the network high impedance and therefore open circuit to any load it is driving.
4. Universal Logic Modules
Components that can implement a varied set of logic functions from a single structure are known as Universal Logic Modules (ULM). They are particularly useful in Programmable Logic Device (PLD) architectures where an array of identical logic cells is replicated across the chip with each cell programmable for a range of required functions. Pass transistor networks are ideally suited to these type of applications since they can provide standard structures with variable functionality determined by the choice of control and data variables.
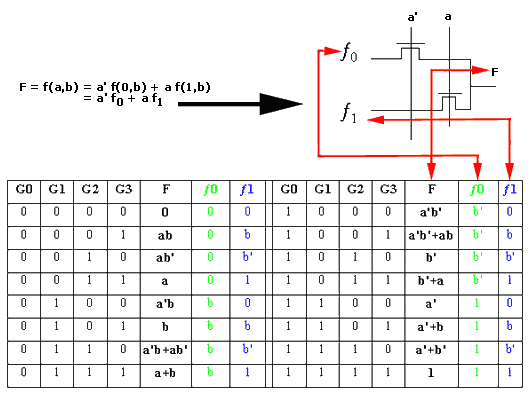
Consider the Shannon expansion for a two variable function.
F = f(a,b)
= a' f(0,b) + a f(1,b)
= a' f0 + a f1
So when a=0, F = f0 and when a=1, F = f1.
By setting f0and f1 to different combinations of logic 0, b and logic 1 we can obtain a variety of logic expressions as shown below.
For example, by setting f0 = 0 and f1 = b the logic expression for the output becomes the AND function
F = a'.0 + a.b = a.b
Figure 1.16 Universal Logic Modules
The function can also be written to use both 'a' and 'b' as the control variables and four binary constants G0 to G3 as the data variables.
F = f(a,b)
= a'b'G0 + a'bG1 + ab'G2 + abG3
This provides a more flexible, programmble implementation as shown below:
Figure 1.17 Universal Logic Modules
So when G0 = G1 = G2 = 0 and G3 =1 all combinations of a and b set F = 0 except a = b =1 which sets F = 1, the AND function.
5. Dynamic Logic
So far all the circuits considered have been static in operation. They rely on a permanent connection to an input logic level to maintain their state. Transistor counts can be further reduced by taking advantage of the inherent charge stored in the circuit devices. Since this charge will quickly dissipate, such circuits have to be constantly refreshed with system clocks. This is now a dynamic operation and such circuits are referred to as Dynamic Logic.
The following circuit details one stage of a dynamic shift register in serial and parallel configurations.
Figure 1.18 Dynamic Logic
The circuit operates in a master/slave arrangement with the first inverter being the master and the second inverter the slave. Two non-overlapping clocks C1 and C2 are required to move data through the register. Since these clocks can never be simultaneously active, C1 will input data to the master and C2 will transfer it to the slave. Hence during the time that C1 is active data will be passed from a previous stage through the first pass transistor and into the master inverter where it will reside as a stored charge. When C2 becomes active this stored charge is transferred through the second pass transistor to the slave inverter and on to the next stage in the register.
The circuit below operates on the same principle but can function both as as a parallel shift register when A = 1 and as a "Divide by 2 circuit" when A = 0.
Figure 1.19 Dynamic Logic
Truth Table
A Output
1 R1 = d1
R2 = d2
Rn = dn
0 R1 = d2
R2 = d3
Rn = 0
Under normal shift operation the inputs d1 to dn are passed from input to output. When in divide mode each bit is connected via an active pass transistor to the next most significant bit. So, for example, if the contents of the register were originally 1100 (12), after the divide operation we would have a new value of 0110 (6).
6. Programmable Logic Arrays
The logic functions so far considered have been relatively simple. Full custom techniques are particularly suited, however, to implementing block functions that have regularly repetitive structures. The Programmable Logic Array (PLA) is an example of such a structure.
Logic functions are typically defined in terms of sum-of-products expressions and these can be mapped easily into a PLA array. The array is a "floor-plan" architecture which consists of an AND-plane and an OR-plane.
The result is that irregular functional designs are mapped onto a regular structure. Design decisions can be delayed until most of the design is complete. The disadvantages of PLAs are that the silicon area used may be large and the circuit performance may be slower than could be obtained by other means.
The area of the array can be determined by the following calculation:
AREA = 2 *( number of inputs + number of outputs) * number of product terms
In general we will need to present both true and inverse variables to the AND plane and take either true or inverse outputs from the OR plane. It is therefore more economical to implement the AND function with inverters and a NOR gate and the OR function with a NOR gate followed by an inverter as shown in the diagram below.
Figure 1.20 Programmable Logic Arrays
Example Design a PLA transistor implementation for the functions:
F1 = AB' + A'CD and F2 = A'CD + AC'
The procedure is as follow:
First minimise the functions and define the product terms. In this case the products terms are: AB', A'CD and AC'
Next generate the AND bit-map (YELLOW) and the OR bit-map (GREEN) tables as shown below.
So, for example, the product term
A'CD will require a connection to the variables A', C and D in the AND plane (indicated by 1s in the AND bit-map) and to F1 and F2 in the OR plane (indicated by 1s in the OR bit-map).
Figure 1.21 Programmable Logic Arrays
The transistor implementation for the PLA is shown below.
Since the AND plane is implemented as a NOT/NOR function it will be necessary to connect a transistor for each 0 in the bit-map.
Similarly, since the OR plane is implemented as a NOR/NOT function, a pull-down transistor is connected for each 1 in the bit-map.
So, for example, the line generating the
AB' product term will be pulled high by the AND plane depletion mode pull-ups if A=1 and B=0 since none of the transistors connected to that line will be active. This in turn will switch on the pull down transistor in the OR plane, setting the input to the F1 inverter low and therefore its output high.
Figure 1.22 Programmable Logic Arrays
7. Weinberger Arrays
The Weinberger array is a product-of-sums implementation using a regular structure of NOR gates to implement the logic function. It can be easily expanded by adding inputs at the bottom and NOR gates to the right without changing the existing structure. The use of NOR gates throughout allows a constant pull-up size.
The pull-ups can be depletion mode devices in an NMOS process or grounded gate P-enhancement transistors in a CMOS process. In either case they must be sized to satisfy the pull-up/pull-down ratio (4:1 in 5V technology).
The array consists of 3 NOR gates in series providing the following functions :-
1st NOR level: Invert the inputs
2nd NOR level: Implement the required logic expression
3rd NOR level: Invert to form the output
Example Design a Weinberger Array to implement the function F = ab + c
First rearrange the function for implementation with NOR gates.
F = ab + c
= (a' + b')' +c by DeMorgan's law
= ((a'+b')'+c)'' by double inverting the expression
So now the 1st NOR level will generate the inverse inputs
a' and
b'.
The 2nd NOR level will implement the function
(a'+b')'+c)'.
The 3rd NOR level will invert this function
(a'+b')'+c)'' for the final output. A suitable circuit for the 1st NOR level is shown below. p-type enhancement mode transistors are utilised as pull up devices. Connecting their gates permanently to Vss ensures that they are always switched on.
Figure 1.23 Weinberger Arrays
We now require a NOR gate to generate the function (a'+b')'. This will form part of the 2nd NOR level. The circuit structure can be extended to include this capability as shown below.
Figure 1.24 Weinberger Arrays
The 2nd NOR level can now be further extended to include the complete logic expression
(a'+b')'+c)' and the 3rd NOR level added to implement the final inversion
(a'+b')'+c)'' as shown below.
Figure 1.25 Weinberger Arrays
8. Static RAM Arrays
Memory devices provide another good example of regular block structures well suited to full custom design.
Static Random Access Memory (SRAM) retains data as long as the power supply is applied.
The standard SRAM cell comprises two back-to-back inverters forming a flip-flop configuration. The cell is selectable by pass transistors connected to a Row Select Line and when in this condition data can be written into or read out from the cell using the Bit Lines. A number of these cells will be arranged in a matrix of rows and columns. Each row will have a common Row Select Line and each column will have common Bit Lines. The logic gate and transistor circuit representations for the cell are shown below.
When not selected the two inverters feed back on each other to reinforce the stored data. So, for example, if the output of the top inverter is a logic 0, this is fed to the input of the bottom inverter which then produces a logic 1 on its output. This is fed back to the input of the top inverter to maintain its current logic 0 output.
Figure 1.26 Static RAM (SRAM) 6 Transistor Cell
Figure 1.27 Static RAM Arrays
Selecting a Cell
Cells are selected a row at a time by activating the Row Select Line. This opens pass transistors T1 and T2 and connects the flip-flop inverters to the Bit Lines. A complete cell row can now be written to or read from.
Writing to a Cell
The required data to be written to the cell is placed on the Bit Lines Ba and Bb. This is arranged so that these lines always contain opposite logic values. We can arbitrarily assign Ba as the true output and Bb as the inverse. So to store a 0 set Ba=0 and Bb=1 and to store a 1 set Ba=1 and Bb=0.
Assume now that the cell is currently in a logic 1 state. Node x in the circuit will be a logic 1 and node y will be a logic 0. To write a logic 0 into the cell we set Ba=0 and Bb=1. Node x is forced to change to a logic 0, switching the output of the top inverter to a logic 1 and reinforcing the logic 1 at node y set by the Bb Bit Line. The bottom inverter output switches to a logic 0, reinforcing the logic 0 at node x. When the Row Select Line is deactivated the cell now remains in its new state. The process is illustrated below.
Figure 1.28 Writing to a Cell
Reading from a Cell
Reading from the cell is a little more involved. As is common with a number of memory cell configurations the process of reading data from a cell can destroy its contents. This is known as a Destructive Read operation and will occur when the cell is selected and both Bit Lines are at logic 0. To avoid this it is necessary to precharge both Bit Lines to a logic 1 prior to cell selection. The following circuit is suitable.
Figure 1.29 Reading from a cell
At the top of each column is a precharge circuit consisting of a PMOS transistor for each Bit Line. When the precharge signal is activated (set to logic 0) the Bit Lines are connected to Vdd and the intrinsic capacitance associated with each line charges up to Vdd.
The cell can now be selected for reading. Assume that the cell is currently in the logic 1 state with node x=1 and node y=0. When the cell is connected to the Bit Lines, Ba will connect to node x and remain at a logic 1 whilst Bb will connect to node y and discharge to a logic 0 as shown.
Figure 21.30 Static RAM Arrays
There now remains the problem of how to capture the logic values on the Bit Lines. For this we use a Sense Amplifier located at the bottom of each column. This amplifies the difference between the Bit Lines as discharging takes place and sets the lines to good logic levels. A suitable circuit is shown below.
Figure 1.31 Sense Amplifier
The circuit implements a cross-coupled inverter arrangement providing a flip-flop function similar to that employed in the memory cell. During the sensing operation the Sense signal will be set high, turning on transistor ts and activating the amplifier. Given that Ba will be a logic 1 and Bb is discharging to logic 0 the output of the left hand inverter will be at logic 0, thereby assisting both the Bb Bit Line to discharge and the output of the right hand inverter to assume a logic 1. The flip-flop is now latched in the required state and the Bit Lines are set to good logic levels. When the cell has been successfully read the Sense signal can be deactivated and the Bit Lines are now available for other operations.
9. Dynamic RAM Arrays
Like the dynamic logic circuits previously considered Dynamic Random Access Memory (DRAM) Arrays require regular refreshing to maintain their contents. This results in slower operation than SRAM but has fewer transistors in the memory cell. A 4 transistor DRAM cell is shown below:
Figure 1.32 Dynamic RAM Arrays
The cell follows a similar construction to the SRAM with Row Select Lines and Bit Lines. The cell maintains its stored data, however, by using the intrinsic capacitance Cg3 and Cg4 of the cell transistors. In time this will decay so a refresh operation is required to top up the charge.
Refreshing the Cell
Before the cell can be refreshed a precharge operation must have taken place. This is accomplished in the same manner as for the SRAM cell. In this condition both Bit Lines will be at logic 1. Next the cell is selected by activating the Row Select Line. Assuming that T3 is off and T4 is on, Cg3 will be discharged (low) and Cg4 will be charged (high). Connecting the Bit Lines will cause Cg4 to recharge high and Cg3 to remain discharged low. The process is shown below.
Figure 3.32 Refreshing the Cell
Writing to a Cell
The cell must first be selected. Assume as before that T3 is off and T4 is on and that we wish to write a logic 0 into the cell. The Bit Lines will be set so that Ba=0 and Bb=1. Cg4 will discharge turning T4 off whilst Cg3 will charge turning T3 on as shown below.
Figure 3.33 Writing to a Cell
Reading from a Cell
The read operation is essentially the same as the refresh operation. The Bit Lines are precharged, the cell is selected and the state of the Bit Lines are captured with a sense amplifier.
Nguồn ami.ac.uk










































{kind=link}